很高兴参加这次活动,之前我一直从事分布式计算;从硕士阶段就开始在做分布式资源的调度及优化这一块,当时是基于Globus做跨机群的资源调度。毕业时加入了百度,后来进入了Platform Computing公司;Platform Computing是一家有着20多年分布式经验的公司;2012年Platform Computing被IBM收购,现在做为IBM一个子部门继续从事分布式相关的工作。凭借我们在分布式方面非常丰富的经验,我们在与分布式相关的开源项目都有比较多的贡献,这次主要讲与Mesos, Kubernetes,Swarm相关,还有其它团队在做Spark相关的项目。我会介绍一下Kubernetes和Swarm与Mesos的集成;比如说在公司的选型上谈一下我自己的想法,大家可以一起交流,如果有一些其他的想法,大家也可以一起讨论。

我先简单介绍一下这三个产品,然后讲一讲为什么要把Kubernetes和Swarm集成到Mesos上;然后介绍一些集成的细节,后面还有一些遇到的Challenge。最后,我们已经有一款自己的产品,叫EGO,和Mesos比较像。后续会逐渐将我们的经验及想法贡献到社区,我们做的主要是资源的调度,提高云和集群中资源的使用效率。

首先介绍一下三个产品;Kubernetes是Google推出的,参考Google Borg的开源实现,现在支持它的有红帽、惠普、华为等企业。Swarm是Docker下的项目,Swarm的目标是100%兼容Docker API,现在已经达到90%多;有些API在分布式环境中比较难处理,后面会有介绍。Mesos是这次演讲的重点,Mesos由Mesosphere公司来支持,第二大的commiter是Twitter,第三大的社区贡献者是IBM。IBM上个季度贡献了200多代码。Mesos主要是为了将资源抽象出来,尤其是CPU这些资源抽象出来,使整个集群看起来就像一台机器;用户只要关心他使用什么样的资源就可以了,这是Mesos的作用,也就是进行资源的调度和编排,提高整个资源的使用率,减少IO,最终降低开发和运维的成本。
我原来在百度的时候,百度的运维团队非常庞大,研发要给他写一个脚本,也就是上线步骤,告诉他第一步怎么办,第二步怎么办,第三步怎么办,运维人员按照这个脚本来执行。业务上线以后,通知研发检查有没有问题。现在跟原来的同事聊,有了很大的变化,很多东西都有自动化的脚本,包括资源的利用,大概需要什么样的资源,它会自动的支撑脚本。Mesos就是做这件事,把整个资源的运维用机器做起来,减少手动。

说一下为什么集成到Mesos上,Kubernetes和Swarm最主要的目标是Container,我们希望对资源可以共享,比如说双十一,会有峰值的时候;系统在平时会有一个估值,提供基本的服务资源;剩下的机器做一些线下的分析。Mesos为这样的需求提供了一种解决方案。
“Auto-Scaling”和“不依赖于特殊网络”;这两种个原因说服力不强:网络自己用脚本就可以做了,Auto-Scaling用脚本也差不多;主要优势还是资源共享,在DCOS上资源共享相对来说比较重要。现在大部分的公司还在专注于网络和存储,可以将容器连接进来并可以访问共享数据;但是过一段时间你会发现,网络和存储不是大的问题以后,大家会关心资源的利用率;如果10台机器的资源利用率提高10%,带来的好处并不明显,但如果是1万台机器能提高10%的利用率,那集群相当于多了1000台机,带来的效果还是很明显的。
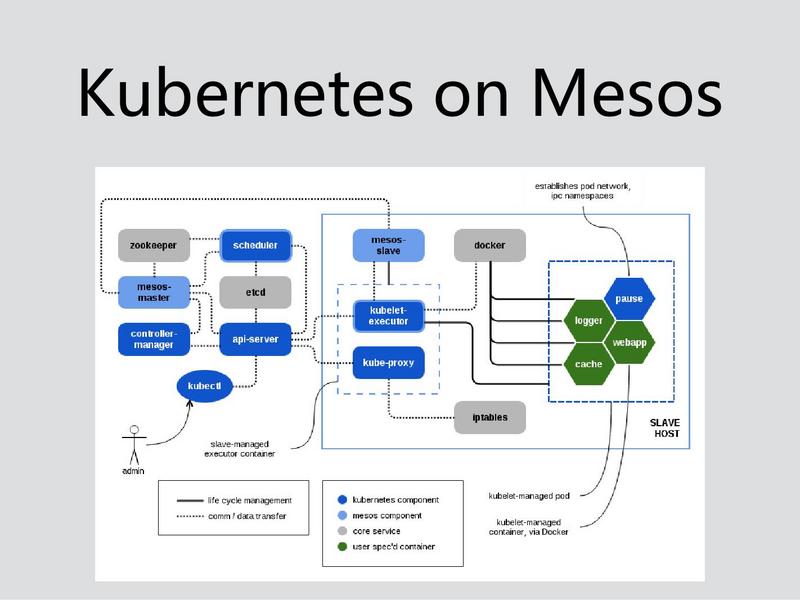
这是Kubernetes在Mesos的一个结构图,Kubernetes最左边这个地方就是Kubernetes自己本身的一些Master的东西,其实在Master最主要的是资源调度Scheduler这一块,Scheduler的资源是Mesos Master分出来的,所以在Kubernetes对Mesos来说只是其中的一个framework,Kubernetes和Spark可以共享资源。Kubernetes提供的CloudProvide很多,它可以跟其他的云厂商可以进行集成。在调度资源里面,Kubernetes还会遵循现有的调度策略。但是有一个问题,就是Scheduler在计算的时候,分配的资源只是基于Mesos给它的东西,比如Mesos分给Scheduler机器A,但是可能机器B上有一个更优的资源,它其实是拿不到的。
Scheduler拿到资源以后还是通过Mesos来启动计算节点,Kubernetes的Master相当于Mesos的一个Framework。这个计算节点的executor其实这个做的还是蛮不错的。在Kubernetes 中提供了一个Kubelet的库用于容器的管理,这个集成项目把Kubernetes和mesos的Executor做了集成,两边做的都是蛮好的。最开始以为是Slave再去起一个Kubernetes 的 Agent,那样计算节点的开销会很大。现在的解决方案相当于是把Kubernetes集中到Mesos的Executor。Kubernetes On Mesos,自己做了Executor,改了Scheduler,基本上还保持了Kubernetes原有的功能,对原来的支持还是蛮不错的。

集成的问题,其实从总体架构来看,大家都是提供了集成的方法,但彼此的集成方案很难统一。而且在概念和功能上也有很大的区别,比如说Namespace和Quota,这是Kubernetes自己的功能,这两个彼此的资源都看不到。但是这个集成方案中,他并没有映射到Mesos自己的Role,整个Kubernetes映射成一个Role,这个Role能拿到多少Quota,就是Kubernetes 的资源。
另外就是刚才说的关于Optimistic Offer、Revocable resources。所谓资源共享,是Mesos上的一个Framework可以把自己不用的资源借出去,但是当我要的时候,我应该可以把资源抢占回来。而且当资源被抢占的时候需要给出一定的时间进行清理。Optimistic Offer现在会直接把资源抢回来,而且没有一个接口通知相应的作业进行后续的清理工作。比如说我要删某一个进程我应该告诉你怎么删,我要做一些东西。Kubernetes没有对Revocable resources做这些相应的处理。
另外,Mesos自己对Revocable Resources的支持力度也不是特别大。现在支持一种Revocable Resource:当机器分出去的Resources,但是没有用,也可以做Revocable resources。现在和Committer交流,我们经常提这个功能,他们并没有意识到资源的使用率对整个集群有多重要。集成的时候,Unified Container,把镜像下下来去解析。作为Unified Container,它并没有提供API, Kubernetes要用Docker的API完成这些工作,如果想把这些引到你的Unified Container,就意味着你的Unified Container要支持Docker的API,这对Mesos来说是很重要的。Docker的API最大问题是并没有一个统一的标准,它的镜像是可以下载下来的执行,但是Docker本身的API没有标准,Mesos的Unified Container要去兼容它的API是一件很繁重的工作。
另外就是Persistent Volume,Mesos自己提供了Persistent Volume,这个作业在机器上重启以后,这个资源所使用的文件会被留下来;如果没有Persistent Volume,则沙箱里的数据都会被删掉,这一块并没有跟Kubernetes自己的Persistent Volume集成在一块,Kubernetes自己的Persistent Volume做的事情是把Volume做成一种资源,比如说是1G或者2G,然后可以请求和作用这些资源;其实跟Mesos的功能是从想法上是完全一致的。但这里有一个效率的问题,Kubernetes自己Persistent Volume能够拿到全局所有的资源,但是如果基于Mesos的话,只能拿到Mesos固定的一些资源,所以这个Kubernetes只能基于不是最优集成拿到最好。其实最主要的大家都有自己的概念和想法,是没有一个人去做两边的集成,大家都认为应该跟随,到底谁应该跟随谁。
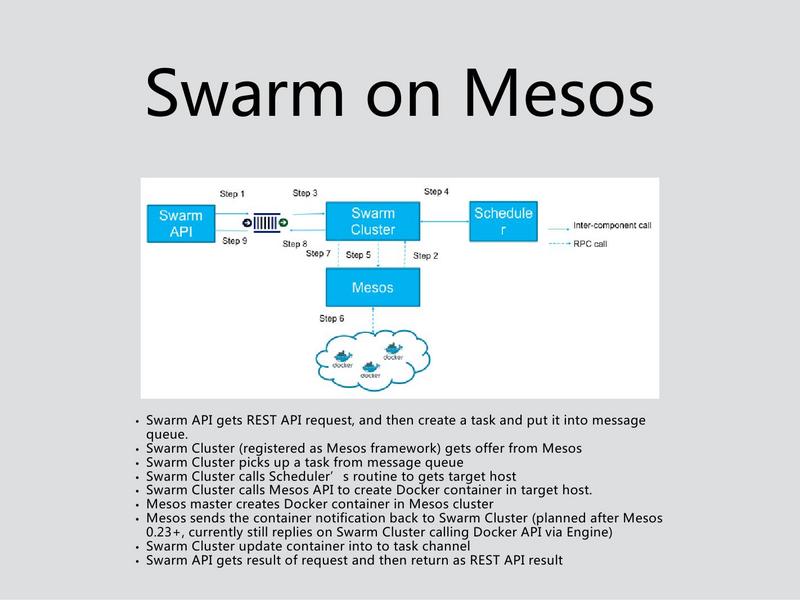
Swarm相对来说还简单一点,Swarm对于资源还好,最开始的时候其实Swarm他会去发一个请求,这个请求还是自己Mesos的系统,他会自己做一个Schedule,告诉Master。因为Swarm运行Docker UPS,有一个路径,所以这个东西资源分配给Swarm Cluster,这个资源分到Swarm,资源分到这,Swarm会告诉他在哪一台机器上,然后Swarm会连这台机器上的Container。再取那个信息,整个的过程是达到Swarm拿到这个机器以后会告诉Master,Run就基于Mesos自己对Docker的支持。透过这个信息也会告诉你连这个Docker,把这个信息盖了,这个集成会比较简单一点。
Swarm这一块相对来说做的稍微好一些,它会抽象成一个集群,它跟Mesos相对来说关系比较好的。但是Swarm本身的功能相对来说比较少,需要依赖于Docker,才能搭一个大的环境。集成的时候,我们有相似的这些东西,也有相似的问题,尤其是Docker API,比如说我先推一个,等我Run的时候,如果那个资源一直留在那儿的时候,这个资源一直留着,因为也不知道什么时候开始,不知道什么时候把容器起起来,这个CPU有可能闲了两天,还是用Mesos其他的功能来弥补。后面有Role和Quota,Swarm在很早的时候不支持Role,Swarm提供了基于Mesos的Role的支持。
现在Mesos和Swarm有一个集成,你经常会看到Kubernetes发一个新的版本,Mesos过两天就说我支持这个版本,最明显的是Kubernetes 1.1,Mesos马上跳出来说我支持1.1了。而Kubernetes最近发了1.2,但是Mesos却没有动静了。
Swarm最新版本我记不住了,Swarm现在还是以Docker为主。其实后面Unified Container对它来说是比较麻烦的一件事情。刚才我们说了Swarm会连机器,如果你用Unifed Container,最后Swarm就没有办法集成。我个人猜,过一段时间Mesos如果这个集成还再继续往前走,Docker Executor有可能会跟Swarm集成放在一块去,不用Unifed Container。其实Kubernetes、Swarm这些都是依赖于Docker镜像做出来的。这一块现在有压力,现在没有一个人跳出来说这个事情到底应该怎么办。
Pesistent Volume包括有一些Role,不知道它后续想怎么去做这些新的东西,因为Swarm现在它们的集成也不是特别的安全。
Challenges这部分,对新的东西的集成,其实这种集成现在跟的特别紧。包括像Security是集成的挑战。Mesos告诉你自己想做什么样的Security就去做,你加一个用户或者改一个权限的话,它俩的集成这一块现在其实还在调查之中,自己玩一玩还好。
Multi-Tenant我刚才也说的,该怎么做决定,尤其是多层级的资源调度。比如说有一个部门,这个部门下面有三个人,每个人用到的资源我们也是在这里做,其实这种role就是一层,如果是三级部门去做这种资源分配还是很好做的。集成我们现在两个在一起做,Mesos我们会推这些资源容器,Kubernetes这一块现在是还在做的一个事情。新的集成这个只能说有新功能找新的解决方案,按案例来做。另外,集成的时候,大家都会用到Kubernetes有自己的UI,这些都是社区的,都是分开的。所以你做Monitoring要自己去做,包括集成的时候,把它的信息全都抓起来观察整个集群的信息,不能单看一个,要把所有的东西全抓住,分析整个系统资源和环境资源,是不是使用率最高的,就是说有没有错误,或者说不是按照小范围来分的。这些都是Mesosphere自己来做的。现在在社区里面其实主要支持这张PPT的上面这三个。

IBM我们自己在做分布相关的产品,我们做了Mesos on EGO,在资源调度、分配、共享等方面有很大的优势。我们在做了Mesos on EGO以后,我们会有一个统一的资源管理系统提供资源计划,资源抢占等;其实我们在EGO里面其实已经做出来了。还有资源的分配,我们原来做企业级的产品,当时最大的客户应该有300多个Role来进行资源的分配和共享。我们现在做这种Policy,我们自己的产品跟Mesos集成,另外一个也会做一些相关的通用的功能。我主要讲的内容就是这么多。谢谢大家!
comments powered by